
Soft Power Squared
GPT and the explosive potential of A.I. parallelism: Part 3

The lightning speed emergence and evolution of OpenAI’s GPT platform, and of large language models (LLMs) in general, requires a reassessment of the innovation landscape and the economy itself. Exciting developments by giant tech companies and tinkering novices land not month by month but minute by minute.
Each new era of digital advance marries a new abundance of hardware resources with an explosion of software creativity. Today, the Transformer approach to A.I., introduced in 2017, leverages the new silicon abundance – massive parallelism, embodied in graphics processors, or GPUs, themselves arrayed in massively parallel fashion in data centers. The result is a new knowledge platform, soon to unleash multidimensional cascades of software, content, and digital capability which will diffuse into every tool and industry.
In 2016, DeepMind’s AlphaGo blew our minds by winning, with panache, an ancient board game far more complicated than chess. AlphaGo signaled a new era in A.I. We noted at the time, however, that it was still playing on a field constrained in multiple dimensions. It also consumed 50,000 times more power than the human brain. An impressive feat, yes, but voracious and narrow.
ChatGPT’s emergence this winter, however, captured the world’s attention because of its seeming ability to deal with a wider range of tasks across a much broader, more ambiguous, more human field of play.
At its most basic, ChatGPT supercharges the search experience. It was trained on a large portion of the Internet’s information up to 2021. But it goes much further. It can write, edit, and suggest, according to theme, tone, or voice. It can make lists, organize events, ace (some) exams but not others, and outline the resources needed for a new project, as it did, in this example, by collating the Amazon Web Service products needed to build a new interactive repository of large audio files. Microsoft is infusing its office and medical productivity suites with GPT.
GPT can write passable software code in many languages. Something called Wolverine, based on GPT-4 ,“gives your python scripts regenerative healing abilities!” – rerunning and debugging itself “until everything is fixed.” An amazing new experiment called AutoGPT expands these capabilities and, through self reflection, can automate the GPT environment to help you better automate your business. These kinds of tools are likely to transform the entire development landscape.
Tinkerers are embedding ChatGPT in other apps and in Excel spreadsheets. In turn, GPT is accepting a wide variety of plug-ins. ChatGPT isn’t great a math, but it can plug-in Wolfram Alfa, which is! It can act as both a broad platform and an add-on feature.
These guys wrote a quick toy prompt to de-bias or un-spin the news – delivering what you might call the Neutral York Times. What ChatGPT is doing with text, of course, DALL-E, Stable Diffusion, and Midjourney are doing with visual content.
We’ve been excited about A.I.’s possibilities in medicine for a decade, and now fun early glimpses are showing up. Here, GPT-4 saved a dog’s life.

The power and extensibility of the new LLMs portends an outbreak of new apps, features, tools, content, companies, and categories. We’ve seen such digital outbreaks before, and this one could exceed all previous.
A New Software Industry
A decade ago, we marveled at the unprecedented explosion of software in the form of mobile apps. In a 2012 report called Soft Power: Zero to 60 Billion in Four Years, we showed that from a standing start, when Apple unveiled the iPhone App Store in the summer of 2008, mobile app downloads grew in less than four years from essentially zero to 60 billion.
The iPhone and then Google Android devices created a new platform upon which to build an entirely new software industry.
In the mainframe era, academics and large businesses wrote custom software programs on punchcards. In the minicomputer era, firms like DEC and Wang delivered a small selection of mostly incompatible business software to firms in large industries. The personal computer (PC) then unleashed a far wider array of “boxed software” from Microsoft and numerous third-parties to a vastly larger market of hundreds of millions. But all those paled in comparison to the smartphone and tablet market of many billions. At the same time, the Internet, Web, and cloud enabled the parallel explosion of software-as-a-service (SaaS) to any device, anytime, anywhere.
The size of this market, we wrote, allowed for a new digital economics.
Smart mobile devices are the most personal of computers. The colossal numbers of these devices, and their connectivity to each other and to all the Internet’s vast resources, creates a market so large and so diverse that the economic forces of innovation and specialization are supercharged. This platform of distributed computation and bandwidth offers unlimited possibilities to create tools and content serving every interest. We call this phenomenon Soft Power.
Apple and Google offered some of their own apps, but the vast majority came from thousands of teams at large firms, small startups, and lots of individual developers, too. SaaS became its own giant venture capital category aimed at both business users and consumers.


In such large markets, even niche products can be big. Layers of software get built inside of and on top of one another. Features and platforms are nested and interlinked in an endless combinatorial playground.
In the digital world, we can build skyscrapers on top of skyscrapers in unbounded architectures that seemingly defy the rules of the physical economy.
The Paralleladigm
The algorithmic innovation of the Transformer model, introduced in 2017, was the fundamental breakthrough. It helped transcend two growing obstacles in the digital hardware realm. As traditionally viewed, both Moore’s Law and the Von Neumann architecture embodied in microprocessors, or CPUs, were slowing down. Shaving each additional nanometer from the width of a transistor was becoming more and more expensive. The cost to build a single chip fab was racing past $10 billion. Meanwhile, the memory bottleneck of the traditional serial Von Neumann CPU, despite adding more cores, was unsuited to the real-time data floods of the visual Internet.
In 2011, we introduced the concept of the paralleladigm – a broad architectural shift across information technologies required to both drive and accommodate the exafloods of real-time data unleashed by the Internet. (Into the Exacloud, 2011.)
“When the network becomes as fast as the processor,” Eric Schmidt famously said, “the computer hollows out and spreads across the network.”
That’s an elegant prediction of what today we call broadband and cloud. But this epochal industrial transformation required a fundamental shift in technology and information architecture. The old copper telephone lines, Von Neumann computer schematic, and client-server network model would not suffice for an era of real-time communication. Entirely new technologies both created the possi- bility of today’s Internet and must advance at a furious pace to merely keep up with Web video, Big Data, and the exacloud.
The common denominator in this new technological paradigm is parallelism.
Over the past two decades, scientists noticed that the actual performance of microchips would not keep up with the addition of more silicon transistors and faster frequencies, growing at the pace of Moore’s law. Slow access to memory meant that billions of transistors and clock cycles were left waiting, doing nothing much of the time. Chips running at ever higher frequencies, meanwhile, consumed way too much power and would melt without expensive cooling methods. This Von Neumann bottleneck meant that chips were getting larger and hotter but wouldn’t deliver the bang for the buck promised by Moore’s law.
Thus the rise of multi-core chips. The multi-core wave was previewed by the rise of graphics processors, or GPUs. Traditional microprocessors, or CPUs, couldn’t deliver the parallel processing power needed for video games. Even the most powerful Intel CPU was not very good at accepting input from a teenager’s joystick and then instantly rendering millions of pixels onto a video display, dozens of times per second. But the new GPUs, from Nvidia and ATI (now part of AMD), were massively parallel, containing dozens of individual specialized processors. Today GPUs are moving well beyond gaming into every digital field, from finance to oil exploration. Often now programmable, there is a new generation of general purpose graphic processors, or GPGPUs.
This paradigm of parallelism would also point the way for A.I.
CPUs were highly programmable and flexible but did not excel at massive data throughput needed in network routing, graphics, or A.I training. “Recurrent neural network” models, the chief approach to A.I. in the mid-2010s, were likewise based on sequential Von Neumann CPU computation. They were good but not great.
One general approach to A.I. was an agent-based model, which sought to emulate human reason or rationality. It was very roughly analogous to the step-by-step logic of a CPU. Another approach was based on massive data, seeking to extract and project patterns based on past experience. One was roughly logical, the other roughly intuitive. Each approach had, and has, strengths and weaknesses. It turned out the latter approach – leveraging massive data troves – was ripe for the technological realities of the moment.1
In their 2017 paper, the Google team noted the fundamental shortcomings of existing neural networks and proposed a new algorithm which better exploited the emerging hardware abundance.2
This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples. Recent work has achieved significant improvements in computational efficiency through factorization tricks and conditional computation, while also improving model performance in case of the latter. The fundamental constraint of sequential computation, however, remains.
…
The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
Now, the parallel construction of both the algorithm and the computing engine would be powerfully aligned, so to speak. The result, several years later, is the biggest leap in A.I.’s seven-decade history.
As venture capitalist Steve Jurvetson’s chart below shows, when Moore’s Law was about to slow in CPUs, the cost-performance of GPUs and similar highly parallel ASICs (application specific integrated circuits) took over.
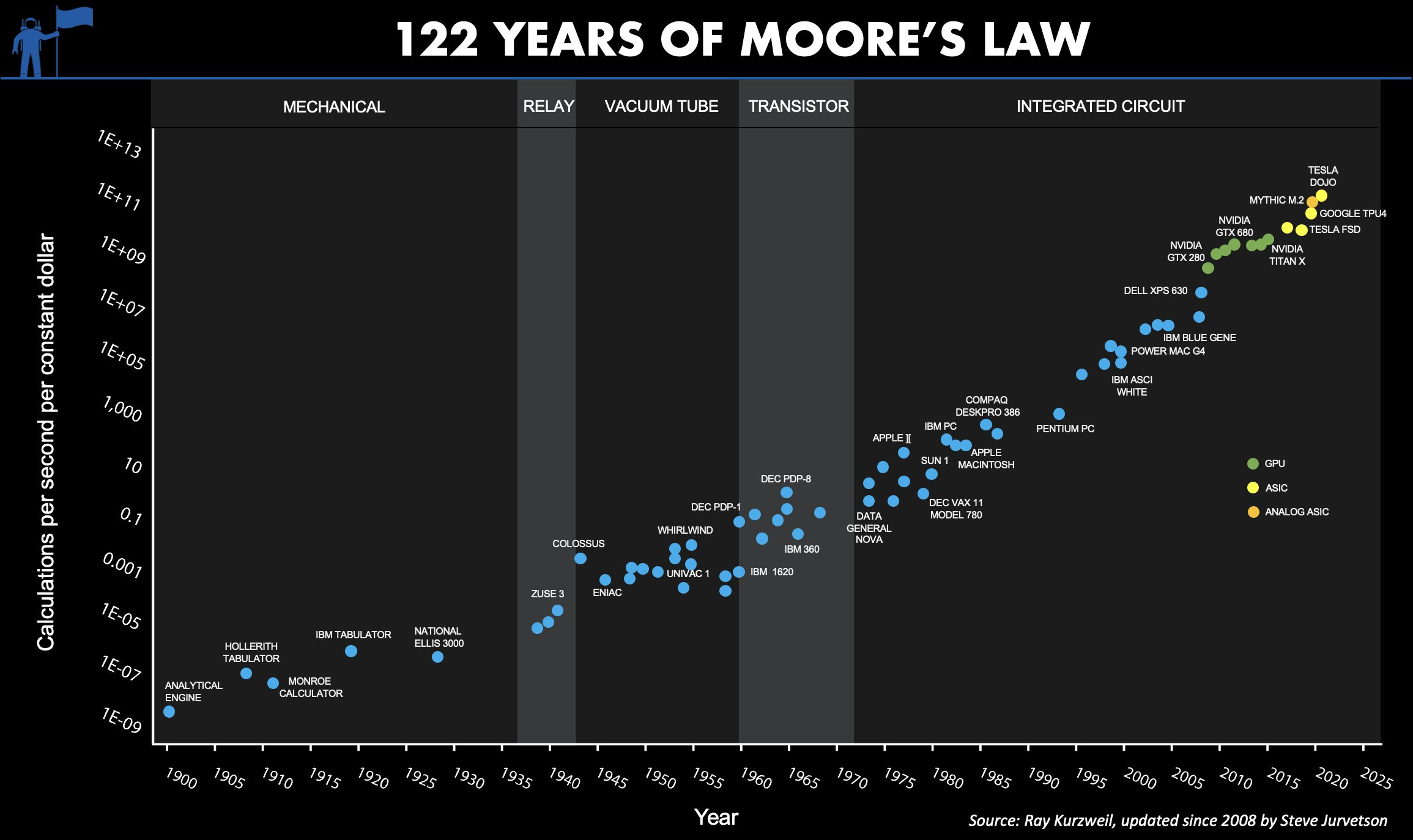
In our 2015 report on the 50th anniversary of Moore’s Law, we noted that extending Moore's Law would likely depend on growing parallelism both in the micro architecture of chips and the macro architecture of warehouse-scale computing.3
A decade ago, as chips started moving to parallel architectures (multiple computing cores) at the micro scale, engineers also began employing parallel computing architectures at the macro scale, linking processors, memory, storage, and software stacks across the data center—and then across numerous data centers—to perform integrated computing functions.
Large language models, such as GPT-4, LLaMA, and Bard are the new cutting edge of A.I. not necessarily because they are the holy grail of digital epistemology, the computational end-state of true human-like intelligence. More likely, they simply best combine today’s abundant resources – giant data troves and parallel computing power – with an ingenious Transformer algorithm, to achieve impressive competence at many varied tasks.
ChatGDP
What do these breakthroughs mean for the economy? We’ll soon have much more to say about A.I.’s impact on productivity, investment, and the structure of tech and business itself. For starters, here is the “GPTs are GPTs” paper, which looks at the possible early labor market effects. Here’s Goldman Sachs on “A.I.’s potentially large effects on economic and productivity growth.” And here is the big 155-page Microsoft paper, ”Sparks of Artificial General Intelligence: Experiments with GPT-4.”
In coming days, we’ll also go deep on the policy questions of so-called A.I. safety. We disagree with the idea of a six month “pause.” Meantime, here are a couple good policy articles to review: “A.I. Alignment and Future Threats” by Brent Skorup, and “A Balanced A.I. Governance Vision for America,” by Adam Thierer.
Until next time…

Series on Artificial Intelligence
How Generative Pre-Training Will Transform the Economy: Part 1
Censors Target Internet Talkers with A.I. Truth Scores: Part 2
Here’s the way we described it in a short 2018 article, “Beyond the Hype on Artificial Intelligence: The Reality of Intelligent Infrastructure and Human Augmentation.”
“We’ve also rethought AI at the most basic conceptual level, exploiting GPU parallelism and vast data troves to come at AI from a different angle. As Matt Taddy of the University of Chicago explains:
Classical AI relied on hand-specified logic rules to mimic how a rational human might approach a given problem. This approach is sometimes nostalgically referred to as GOFAI, or ‘good old-fashioned AI’. The problem with GOFAI is obvious: solving human problems with logic rules requires an impossibly complex cataloging of all possible scenarios and actions. Even for systems able to learn from structured data, the need to have an explicit and detailed data schema means that the system designer must to know in advance how to translate complex human tasks into deterministic algorithms.
“Instead of trying to reverse engineer the human brain and our notions of logic and reason, the new architecture of general purpose machine learning (GPML) avoids human complexities we still don’t understand but actually gains the “capability of working on human-level data: video, audio, and text.” This, Taddy concludes,
is essential for AI because it allows these systems to be installed on top of the same sources of knowledge that humans are able to digest. You don’t need to create a new data-base system (or have an existing standard form) to feed the AI; rather, the AI can live on top of the chaos of information generated through business functions. This capability helps to illustrate why the new AI, based on GPML, is so much more promising than previous attempts at AI.”
George Gilder often explained the winning strategic play in a technological era was to “waste abundance,” in other words to fully leverage the technological resource growing fastest in number and dropping fastest in price – even to the point of apparently excessive waste – while conserving what’s scarce.
Here’s a longer excerpt from the Moore’s Law at 50 paper on the way macro parallel architectures would complement micro parallel architectures:
“A decade ago, as chips started moving to parallel architectures (multiple computing cores) at the micro scale, engineers also began employing parallel computing architectures at the macro scale, linking processors, memory, storage, and software stacks across the data center—and then across numerous data centers—to perform integrated computing functions. Supercomputers had used some of these cluster-computing techniques for decades, but they were few in number and used for niche applications. The rarity of supercomputers and a lack of adequate communications bandwidth meant the advances in parallel hardware architectures, and the programming of these parallel computers, came slow.
“Fiber optics, gigabit Ethernet, and broadband access networks, however, would fundamentally trans- form our computing architectures. “When the network becomes as fast as the processor,” Eric Schmidt said in the early 1990s, nearly a decade before joining Google, “the computer hollows out and spreads across the network.” Or, as Schmidt’s then-employer Sun Microsystems stated in its motto, “The Network Is the Computer.”
“Mead also presaged this development, in more tech- nical terms:
In any physical computing system, the logical entropy treated by classical complexity theory is only part of the story. There is also a spatial entropy associated with computation. Spatial entropy may be thought of as a measure of data being in the wrong place, just as log- ical entropy is a measure of data being in the wrong form. Data communications are used to remove spatial entropy, just as logical operations are used to remove logical entropy. Communications is thus as fundamental a part of the computation process as are logical operations.
“The vision was compelling. But coordinating thousands of servers and data dispersed across the globe was a huge challenge. Google achieved major advances with its Google File System and MapReduce paradigms, which empowered disparate computing resources across the cloud to talk to one another and act as a single large computer when needed, or to split up varied smaller tasks based on the needs of end users on their PCs or smartphones. The company has con- tinued to innovate in parallel architectures and pro- gramming for its own web services, like search and Gmail, and for its third-party cloud services, such as Compute Engine and Google Storage. Amazon Web Services, however, is the largest provider of cloud services and now employs some two million computers in its cloud offerings alone.
“In keeping with Moore’s original vision of radically low-cost computing, the pricing of these cloud services is often measured in pennies. We are extending the economics of Moore’s Law from the microcosmic chip to the macrocosmic data center. When we link computing and memory resources with light-speed optics, we are, in a rough way, building “a chip on a planet.” The move to multicore chips was a way to relieve chips of the growing heat burden at the micro scale. Warehouse scale computing extends this function to the macro level: the massive, centralized air conditioning operations that cool servers in our data centers in effect remove heat from our smartphones and mobile devices.60 This—the physics of computation—is the only fundamental limit on the information economy.”
I woke at 2am as usual last night and listened to the radio chuntering on. A woman with an American voice was saying how her company used AI to detect AI in governments statements,in public safety advice,in marketing propaganda etc,the programmes she had developed could detect when AI was being used to subtly influence the populace. And I'm thinking since the dawn of time every one ever has sought to influence the populace with fake or fraudulent or bad ideas,humanity never needed AI to do that. Like,all you young men,all enthusiasticly sign up to die for your country. It worked for WW1. Men reluctantly and with resignation signed up in WW2,there wasn't an alternative anyway. Now I'm seeing and hearing that age old idea being talked up again. If we don't stand up to the aggressive expansion of Russia we're all doomed. So now what I'm hearing from this lady is that governments and big businesses will sign contracts with her (that's where the money comes from) and her company will use the programs developed by her and her colleagues to scan everything and indicate what is AI generated. So I'm thinking oh great,make everything more complicated and money
generating. Instead of just screwing it up and throwing it in the bin,free and takes minutes,you have to go through this daft money generating procedure. It's all a huge con.
Please…… Help Fight Against the Sale of Children for the Purpose of Sex Trafficking and Child Pornography
1. Watch this entire trailer……
2. Go see this movie when it opens on July 4th, and………
3. Consider Paying it Forward
The Sound of Freedom
https://www.angel.com/pay-it-forward/sound-of-freedom
This is a true story. I watched an hour long interview with Tim Ballard, the subject of this movie, and Jim Caviezel. Tim quit his job as a Department of Homeland Security Special Agent so that he could literally, 'save the kids'.
He is 'The Real Deal'. Jim Caviezel is the actor who plays him in this movie.
These men are literally doing 'God's Work', Tim, by performing this work, and Jim by shining a light on this literal EVIL that is among us. For instance, at my workplace, two men were fired and incarcerated within the last 6 months for child pornography. That happened because they were 'incautious' enought to watch it on a government computer. Think of how many are watching on their private computers, and don't get caught. This is a huge problem worldwide, and our country is a primary contributor to this (no other word for it but)…….. Pure Evil.
We have a moral obligation to do what we can to fight against this….
Please help.
Please take a material step and stand up for goodness, on this Independence Day.
Thank you, Elizabeth